最易懂版糖基化蛋白质组学研究

对于研究糖基化蛋白质组学的学者们来讲,很多人喜欢用sweet这个词来形容自己的研究课题。我个人也很喜欢这个单词,这是一个让人感到幸福而温暖的词语,会让你对你的课题充满了爱意。
但回头想想,当初懵懵懂懂读到研究生,误打误撞进入蛋白质组学圈,好像也就是随大流的主动抑或是被动选择了博士阶段的课题,期间有艰苦,有迷茫,也有收获,有喜悦。话扯远了,就让我们进入今天的话题,谈一谈糖基化蛋白质组学发展到了今天,我们所能做的,和我们想要做的,希望能给领域内的研究者们带来一点点的启迪,也让不熟悉这个领域的科研工作者们对糖基化蛋白质组有个粗略的印象。
在讲糖基化蛋白质组之前,先提一下什么叫做蛋白质组。可能对于即便是不懂科研的老百姓来说,基因组已经是耳熟能详的词汇了。但谈到蛋白质组,好多人就懵圈了。用较为通俗易懂的话来说,蛋白质组是指一个细胞或者一种组织或者一类器官甚至是某一物种所表达的全部蛋白质。
实际上,生物体内蛋白质组的表达是一个动态变化的过程,在这一瞬间和下一瞬间,都是不一样的,也许是同一种蛋白质的表达量发生了变化,也许是其中所表达的蛋白质种类发生了变化。听起来,这就很复杂了对不对?可是要知道,研究作为其中一个子集的糖基化蛋白质组,更是一件难上加难的事。为什么这么讲?
那就让我们先来了解一下糖基化修饰是如何发生的。对于一个特定蛋白的表达,会经历从DNA到mRNA的转录、转录后加工、最后翻译成蛋白质的一系列过程。而当蛋白质被正确表达、剪切、折叠后,很多蛋白会进行一个我们叫做翻译后修饰(post translational modification)的过程,而后才成为具有相应生理功能的成熟蛋白。这也就是我们为什么常常说One Gene, Many Proteins的缘由。在真核生物体内已经发现的翻译后修饰有好几百种,其中研究得比较广泛的应该是磷酸化、糖基化、甲基化、乙酰化、泛素化等。
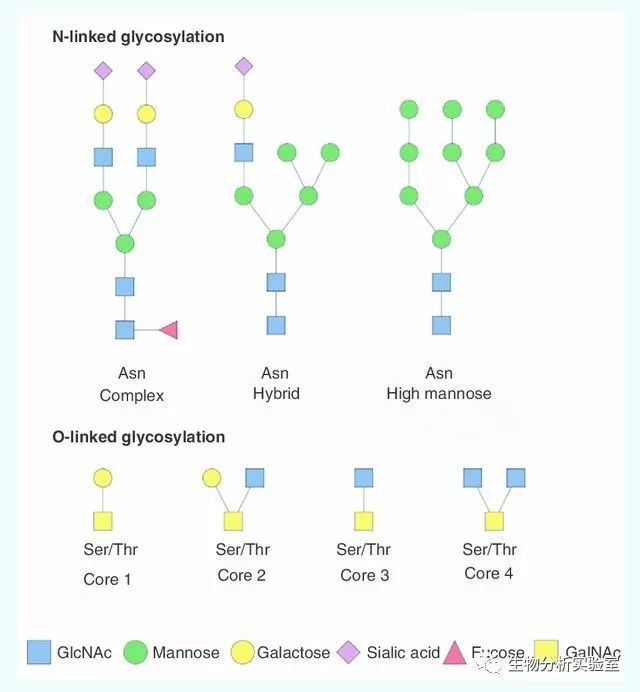
其中,糖基化修饰应该算得上是其中比较复杂的一种了,不像很多其他修饰可能只是在某一种或几种氨基酸上的侧链上增加一个共价结合的分子量固定的基团,糖基化修饰可能发生在天冬酰胺Asn的侧链氨基(-NH2)上(符合N-X-S/T, X≠P的序列规律,称为N-连接糖基化修饰)或者发生在丝氨酸Ser或者苏氨酸Thr的侧链羟基(-OH)上(称为O-连接糖基化修饰),而每一个修饰位点的糖链可能存在多种不同的糖型(笔者按:以上为最主要的两大类糖基化修饰类型,另外还有C-连接糖基化修饰、GPI锚定连接糖基化修饰等)。
用直白一点的语言来说,就是每个可能发生糖基化修饰的位点(不论是哪种类型的糖基化修饰)都可能接上非常多不同种类的糖链(图1列出了N-连接糖基化修饰的三大类——高甘露糖型high mannose、杂合型hybrid和复杂型complex以及最常见的四种O-连接糖基化修饰的核心结构——core 1, 2, 3, 4)。你可以想象,本来是一堆一模一样的光秃秃的蛋白(当然这是种夸张的说法啦),在它们的第123位氨基酸上有个糖基化修饰位点,于是一堆同样的蛋白根据所带糖链结构的不同分成了好几十堆,这一堆带一种糖链,那一堆带另一种糖链,以此类推……天啦噜,想想就觉得很复杂很头疼,对不对?
别急,你以为这就是坑了,那请你小心驾驶,前方有更大更深的坑呢。嗯,我还是试着用比较通俗一点的语言来阐述接下来的问题吧。还是老规矩,先给大家介绍一下经典的蛋白质组学shotgun研究策略。
如图下所示:
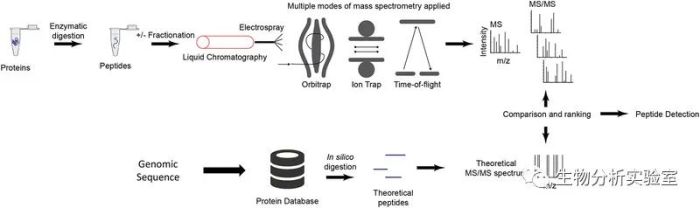
当我们从研究对象(细胞、组织、血液样本等)中提取了全蛋白,通常会选用合适的酶(最常用的是胰酶trypsin或者Lys-C酶)将蛋白酶解成肽段,为了提高蛋白质组的覆盖深度,可以先将肽段进行分级处理(也就是采用合适的色谱分离方法将一个样品分成数十个馏分,当然你完全可以省略这一步),而后将得到的不同馏分或者整个肽段混合样本进行RPLC-MS/MS分析(即反向分离后进行串级质谱鉴定),从而得到数十万甚至上百万张二级谱图。将这些二级谱图,与基于该物种基因组数据推导而来的蛋白质序列经过模拟酶切(in silico digestion)后得到的理论谱图进行比对,即可确定我们的研究样本中究竟有哪些蛋白质存在。如果这个过程大家理解了,那么我想告诉大家的是,在某一个样本中,必然同时存在含量高的蛋白和含量低的蛋白。含量高的蛋白我们通常称其为高丰度蛋白,含量低的蛋白则为低丰度蛋白。前面说,蛋白质经过糖基化修饰这一步,才会在其某些位点上带上糖链。必须指出的是,虽然有很多蛋白都会发生糖基化修饰(在真核生物体内这个比例甚至可能高达50%),但发生糖基化修饰的蛋白质的含量是非常低的。也就是说,很多蛋白都发生了糖基化修饰,但对每个蛋白而言,只有极少一部分发生了糖基化修饰。最最关键的是,发生糖基化修饰的这部分蛋白又不是完全一样的,有些带上这一类糖链,有些又带上那一类糖链。因此,当糖基化肽段和非糖基化肽段同时被离子化,而后进入质谱进行检测时,必然是高丰度的非糖基化肽段被检测到的可能性更高。如果质谱花了时间和精力在高丰度的肽段上,那么低丰度的肽段则会被妥妥忽略,更别提糖基化肽段的离子化效率会相对更低一些,也就更难被检测到了。
以上所说的是由于糖基化修饰本身所带来的研究难点。面对这种困难,研究者们选择的是在进行质谱分析前对样品进行特殊的操作处理,我们把这种处理步骤称之为富集(enrichment)。糖基化蛋白质组学研究发展到了今天,各种富集方法和富集策略早已发展得十分成熟,且应用于各种实际样本中,获得了成功。
简而言之,常见的富集技术就是那么几类(可参考文献Specific enrichment methods for glycoproteome research. Lijuan Zhang, et al. Anal Bioanal Chem (2010) 396: 199-203.):凝集素亲和色谱法、免疫亲和色谱法、亲水性相互作用色谱法(HILIC)、酰肼化学固相萃取法、硼酸固相萃取法等。不同的富集方法,各有其优点及固有局限。像凝集素亲和色谱法、免疫亲和色谱法和硼酸固相萃取法在某些领域非常受欢迎,而在大规模糖蛋白质组学研究时,研究者们可能更偏爱酰肼化学法和亲水性相互作用色谱法。在糖基化蛋白质组学研究发展的初期,酰肼化学法因其超高特异性而深受青睐。继2003年Zhang Hui教授发表了第一篇基于酰肼化学富集法的糖蛋白质组研究工作后,不仅有后来者沿用其原理在技术本身上做了创新性的工作(Highly specific enrichment of N-linked glycopeptides based on hydrazide functionalized soluble nanopolymers. Lijuan Zhang, et al. Chem. Commun., 2014, 50, 1027-1029.),酰肼化学富集法同样被应用于DIA技术研究糖蛋白组的工作中(Yansheng Liu,et al.Molecular & Cellular Proteomics,2014,13,1753-1768.)。然而,酰肼化学富集有个固有的缺陷,那就是经过酰肼富集的糖基化蛋白/肽段上的糖链结构遭到了破坏,只能得到糖基化位点的信息。至于该位点上到底有哪些种类的糖型结构,我们一无所知。当然,这在前几年,质谱硬件条件和软件算法都还没对完整糖肽解析有特别贡献的情况下,采用高特异性的酰肼富集方法,我们能够在蛋白和肽段层面对糖基化修饰进行大规模的定性定量研究,这就极大的推动了糖基化蛋白质组的研究进程了。
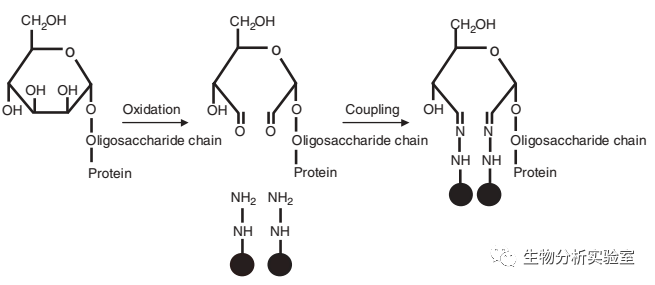
(酰肼化学法原理,摘自Nat Biotechnol. 2003 Jun;21(6): 660-666.)
而在今天,自从Thermo推出了Orbitrap Fusion Tribrid质谱后,不论是仪器本身的高精度、高灵敏度、高分辨率、超高速度的扫描,还是碎裂模式、能量调节方面,可以说都提供了较为理想的硬件条件,间接的也对糖基化蛋白质组研究起了非常大的促进和推动作用。再有一个,更多的研究者们开始将注意力转向糖基化肽段上糖型的变化,为此在分析方法、仪器参数设置、数据处理算法方面都做出了巨大的努力和贡献。
2017年,复旦大学的杨芃原教授和中科院计算所的贺思敏教授课题组在Nature Communications上联合发表了采用国内自主研发的pGlyco软件实现了大规模完整糖肽的精确解析工作,在一次实验中同时完成肽段、糖链、完整糖肽三方面的定性与定量分析,并且能够控制三个层面上的低假阳性率检出,可以说是极大程度的提高了当今完整糖肽的质谱鉴定水平。
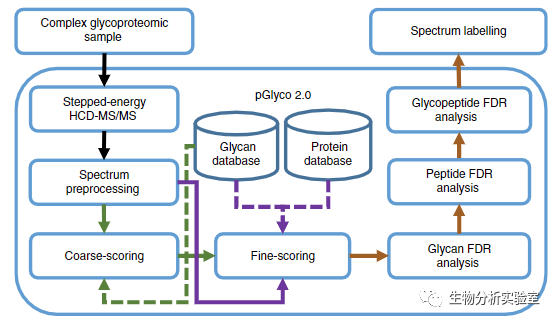
后修饰蛋白质组学一直算得上是蛋白质组领域内难度和挑战性最高的分支课题了,这其中尤以糖基化蛋白质组更是让人又爱又恨。回溯整个糖蛋白质组学的研究进程,可以很清楚的看到,初期大家将目光和重点放在发展各项糖基化蛋白/肽段富集新技术上,并力图将这些技术应用于实际样本的大规模糖基化位点的研究中。
而后,随着各项富集技术的不断优化和成熟,同时伴随着质谱仪器的更新换代以及软件算法的日新月异,研究者们不再止步于修饰位点的鉴定,更多的考虑的是在完整糖肽水平去深入挖掘更有意义的数据,因为大量的研究表明特定修饰位点上糖型的变化很可能预示着某些生理功能的改变,与疾病的发生发展密切相关。
当然,我们现在谈到的都是N-糖基化蛋白质组学研究。至于O-糖基化蛋白质组,我只能很遗憾的说,其发展远远落后于N-糖基化蛋白质组,这是与O-糖基化修饰本身的特点密切相关的(O-糖基化修饰种类繁多,位点没有保守序列,糖链结构也更为复杂,数据库信息非常有限),在不远的将来,这也必然是研究者们会重点关注和投入力量的领域。
生物分析实验室
展源
何发
相关文章
-

AAS法分析茶叶中的铅,镉,砷
2020-05-27
-
检测有机氯类农药,气相色谱法检测法
2021-01-12
-

质谱检测法与蛋白质分析
2020-05-27
-

蛋白质印迹法实验的要点
2021-01-12
-

紫外分光光度法测定蛋白质含量
2020-05-27
-

QC, IQC, IPQC, QA,到底是什么鬼?
2020-05-27
-

色谱峰裂分,前拖尾的诊断
2020-05-27
-

蛋白质相互作用研究
2020-05-27
-

简单有效的酸消化法
2020-05-27

加载更多