标准曲线是大家做定量分析时的常用工具,标准曲线的准确影响着后续数据的处理。今天小编帮大家整理了11个关于标准曲线的快问快答,小细节也要注意呀!
不能。
通常的标准系列多是配制0,1,2,3mg/L系列这样的说法,没做实验人为添加(0,0)很不妥,因为很多时候0管进入仪器可能也有响应值,这也是我们考察试剂空白的一个重要步骤。这个0管在某些时候非常重要,比如全血铅测定,我们采用牛血清来基体匹配标准系列,如果此时你用酸做空白或û做实验人为添加(0,0),那你就很难做好标准曲线。所以标准曲线的0管也是做好标准曲线的重要考虑点。
不需要。
仪器测出来标准系列的响应值可以减掉试剂空白或减掉0管的响应值来做,工作中我们也常用0管来做仪器调零。其实没有必要那么麻烦,即使空白或0管有响应值,在构建标准曲线时,我们已经认为该响应值就是0浓度,也就是扣除了这个空白的。
标准曲线我们通常采用的是Y=a+bX,曲线拟合完必须要做统计检验,且要做统计完备的线性检验和失拟检验,然后再做a与0的差别检验,如果a与0的统计学上无差异,你就可以考虑用Y=bX的拟合曲线,拟合出来后同样做线性检验和失拟检验,如果线性检验合格(P<0.05)且失拟检验合格(p>0.05)此时你就可以采用Y=bX。二次曲线的采用同样是这样的道理,如果你Y=a+bX时拟合不合格,你就考虑用Y=a+bX+cX2,同样做失拟检验,考察拟合的符合情况。如果Y=a+bX 和Y=a+bX+cX2都满足拟合检验和失拟检验合格,则采用Y=a+bX形式,这样符合统计学上参数最少的统计简洁性原则。
标准曲线去查含量时是先减空白信号算样品含量还是先算出空白含量相减呢?
工作中我们常要减掉空白得到样品含量,现有国家标准方法有的推荐先算出空白含量,用样品含量相减,也有推荐先用样品信号减空白信号然后去标准曲线推算含量。而且这两种算法常常差距很大。其实这种差距往往是低含量水平时才出现,在低含量水平通过标准曲线推算含量时,本身不确定度就很大。这两种方法都可以。个人推荐先用样品信号减空白信号然后去标准曲线推算含量,因为这样出来的含量不确定度要小一些,而先算出空白含量再相减就增加了1次标准曲线推算含量时的不确定度,因为好的测量永远是不确定度小的测量。
1.先从原理上讲:判断两条或多条标准曲线的差异,须检验残差,截距和斜率三项,分别有不同的统计学参数,残差用F检验,截距和斜率采用较为复杂的统计量。
2、从实际操作讲:多用协方差分析检验截距和斜率的差异,以SPSS为例:
①先重新整理数据,将y2数据列加到y1下面,变成一个变量y;将x2数据列加到x1下面,变成一个变量x;然后再设定一个新的分组变量group,原来第1组值为1,第2组值为2。
②进行协方差分析(第一步分析斜率是否无差异).Analyze->GeneralLinear Model->Univariate Dependent List:填入y—将y做为因变量 Fixed Factor:填入group Covaraites:填入x—将x做为协变量 Model:选Custom Model:填入 x groupx*group—注意如果变量填入顺序不一样,结果也会不一样. Sum ofsquares下拉列表框:选TypeI 然后点击ok,看结果里x*group这一行的Sig.P值,若大于0.05,则接受原假设,即两条回归直线的斜率无差异,否则拒绝。
③再来进行截距的无差异分析其实过程跟上面一样,只是Model里去掉了x*group交叉项.Analyze->GeneralLinear Model->Univariate Dependent List:填入y—将y做为因变量 Fixed Factor:填入group Covaraites:填入x—将x做为协变量 Model:选Custom Model:填入 x group—注意如果变量填入顺序不一样,结果也会不一样. Sum of squares下拉列表框:选TypeI 点击ok后,看group一行的Sig.P值,若P值大于0.05说明两条回归直线截距也无差异,若小于0.05说明截距是有差异的。
标准溶液体积取用的有效数字跟你采用的体积量具有直接关系。比如说量取或准确量取等字眼,10mL和10.0mL提示你要采用不同的量具。
当我们使用某个量具完成某次体积取用后,读数是按照量具的最小允差决定的,而最小允差是针对最小分度线而言的。
当取用10mL体积时,如果用A级10mL的分度吸管,那ô10.0mL应该是确定的,因为它的分度线为0.1mL。
当取用1mL体积时,如果用A级1mL的分度吸管,那ô1.00mL应该是确定的,因为它的分度线为0.01mL。
所以我个人意见,到底写10.00还是10.0以最小分度线来确定,最小分度线以下的都为估读。如果你认为估读也是有效数字的话,10.00mL也可以,因为此时的容量允差为0.05mL,但1.000mL就û有太大意义了,因为A级1mL的分度吸管的容量允差已经是0.008mL了。
GB5750.3-20068.2.7项有如下规定:校准曲线相关系数只舍不入,保留到小数点后出现非9的一位,如0.99989→0.9998。如果小数点后都是9时,最多保留小数点后4位。
标准系列一般都是配制不同浓度,进样相同体积来做的(浓度法)。但实际工作中我们还用到同一浓度来进样不同体积的方式来做(体积法),浓度法与体积法的区别在于浓度法中与待测物质存在的溶剂/待测物质的比例与体积法不同。浓度法中溶剂的环境(体积)基本是一致的,这样的好处就是浓度法在判断溶剂(或溶剂中干扰物质)和待测物质的指认上更加容易。体积法中干扰物质也会随标准系列增加,不容易实现待测物质的指认。从进样针,进小体积时不确定度比较大,带来的直接结果时标准曲线不如浓度法容易做直。而且物理体积的限制,体积法不太容易实现较大跨度的浓度系列设置。总之,体积法和浓度法本质上是一致的,但浓度法有:容易做好标准曲线,容易实现较大浓度跨度和容易实现待测物质的指认等优点。
这种情况下我们一般选择四种方式报告结果:未检出,<检出限,<定量限,<标准曲线第一点所推算的样品浓度。
四种都有道理,实际区别是埋在四种选择下面的结果报告人的风险。
未检出的全部含义应该是本实验室本仪器本方法为检出,如果没有这些界定,未检出的歧义很多,而且没有提供其它任何可用的信息。
所以建议一般不采用这种报告方法;
检出限是定性检出的标志,它是跟空白的统计比较计算出来的。
一台仪器,每次测定都有其检出限,检出限计算目前有两大类计算方法:单浓度方法和校正设计法(Anal.Chem.1997,69:3069),常规采用的单浓度方法需要额外的工作,所以现在趋向用校正设计法,既利用标准曲线直接计算检出限,但检出限I类和II类错误皆控制在0.05。
定量限是可以定量检出的标志,其RSD定为10%,其II类错误比检出限小很多。<标准曲线第一点所推算的样品浓度,是我们仪器比较可信的测定浓度。总之,报告<检出限,<定量限,<标准曲线第一点所推算的样品浓度所犯I类和II类错误依次降低,但如果这个报告结果已经超过你要判断的限值,那么你的检测就一点意义都没有了。所以现在的检测单位甚至直接报告小于国家标准规定的限值,从概率统计的角度讲,它犯错误的几率最小,但又解决了客户的检测问题。
空白代表你所选择的空白对仪器响应/信号的影响,当然可能是正方向和负方向的影响,所以理论上讲必须减掉空白。至于是先减空白信号,还是减空白测定值,按国家规定或参见4问题。
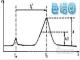
配制一系列浓度标准,包括0浓度,从低浓度开始拟合当拟合检验出现P>0.05的最高的那个浓度点为止。有也经验说当加入的高浓度点在低浓度
点构建的直线方程推算的响应超出±10%范围。关于线性范Χ的最低点应该是0、检出限或是定量限的问题,个人趋向最低点为0,因为线性范围只是统计学上线性的表现,跟能否准确定量是两方面的问题。

.jpg?x-oss-process=image/resize,m_pad,w_80,h_60,color_eeeeee)







加载更多